
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- consumer
- Spring Security
- Java8
- Stream
- mokito
- optional
- Java
- #패스트캠퍼스 #환급챌린지 #패스트캠퍼스후기 #습관형성 #직장인자기계발 #오공완
- 패스트캠퍼스 #환급챌린지 #패스트캠퍼스후기 #습관형성 #직장인자기계발 #오공완
- Authentication
- TDD
- git cli
- SpringBoot
- orelse
- Clean Code
- 카프카
- JWT
- 디자인패턴
- signWith
- 싱글톤
- orElseGet
- 인텔리제이 단축키
- kafka
- junit5
- effective java
- Functional Programming
- topic
- Factory Method Pattern
- producer
- 함수형 프로그래밍
Archives
- Today
- Total
goodbye
패스트캠퍼스 환급챌린지 35일차 : 테디노트의 RAG 비법노트 강의 후기 본문
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다
https://fastcampus.info/4n8ztzq
(~6/20) 50일의 기적 AI 환급반💫 | 패스트캠퍼스
초간단 미션! 하루 20분 공부하고 수강료 전액 환급에 AI 스킬 장착까지!
fastcampus.co.kr
패스트캠퍼스 환급챌린지 35일차!
1) 공부 시작 시간 인증

2) 공부 종료 시간 인증

3) 강의 수강 클립 인증

4) 학습 인증샷
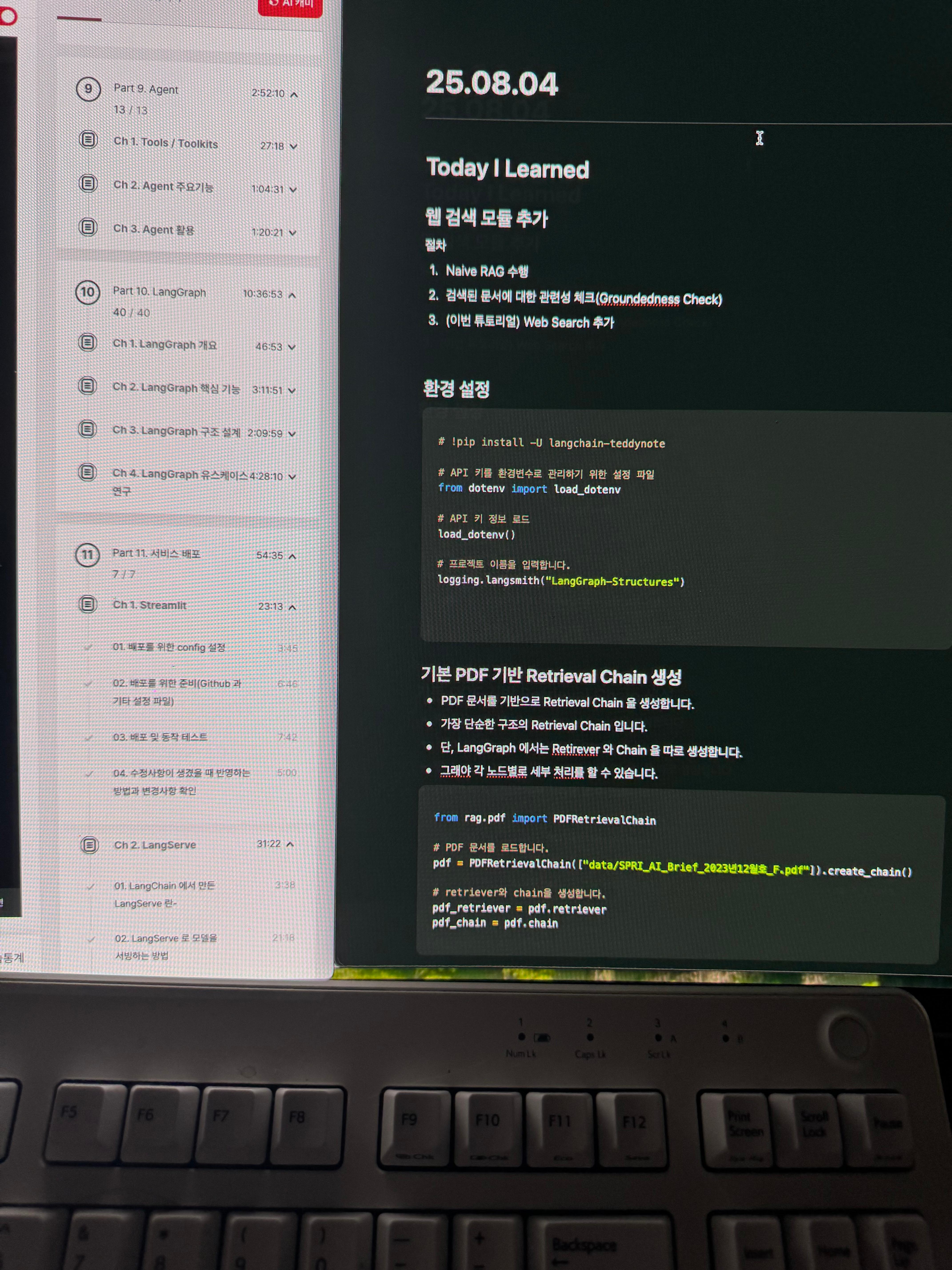
5) 학습통계

Today I Learned
웹 검색 모듈 추가
절차
- Naive RAG 수행
- 검색된 문서에 대한 관련성 체크(Groundedness Check)
- (이번 튜토리얼) Web Search 추가
환경 설정
# !pip install -U langchain-teddynote
# API 키를 환경변수로 관리하기 위한 설정 파일
from dotenv import load_dotenv
# API 키 정보 로드
load_dotenv()
# 프로젝트 이름을 입력합니다.
logging.langsmith("LangGraph-Structures")
기본 PDF 기반 Retrieval Chain 생성
- PDF 문서를 기반으로 Retrieval Chain 을 생성합니다.
- 가장 단순한 구조의 Retrieval Chain 입니다.
- 단, LangGraph 에서는 Retirever 와 Chain 을 따로 생성합니다.
- 그래야 각 노드별로 세부 처리를 할 수 있습니다.
from rag.pdf import PDFRetrievalChain
# PDF 문서를 로드합니다.
pdf = PDFRetrievalChain(["data/SPRI_AI_Brief_2023년12월호_F.pdf"]).create_chain()
# retriever와 chain을 생성합니다.
pdf_retriever = pdf.retriever
pdf_chain = pdf.chain
State 정의
- State: Graph 의 노드와 노드 간 공유하는 상태를 정의합니다.
- 일반적으로 TypedDict 형식을 사용합니다.
- 상태(State)에 관련성(relevance) 체크 결과를 추가합니다.
from typing import Annotated, TypedDict
from langgraph.graph.message import add_messages
# GraphState 상태 정의
class GraphState(TypedDict):
question: Annotated[str, "Question"] # 질문
context: Annotated[str, "Context"] # 문서의 검색 결과
answer: Annotated[str, "Answer"] # 답변
messages: Annotated[list, add_messages] # 메시지(누적되는 list)
relevance: Annotated[str, "Relevance"] # 관련성
노드(Node) 정의
- Nodes: 각 단계를 처리하는 노드입니다. 보통은 Python 함수로 구현합니다. 입력과 출력이 상태(State) 값입니다.
참고
- State를 입력으로 받아 정의된 로직을 수행한 후 업데이트된 State를 반환합니다.
from langchain_openai import ChatOpenAI
from langchain_teddynote.evaluator import GroundednessChecker
from langchain_teddynote.messages import messages_to_history
from rag.utils import format_docs
# 문서 검색 노드
def retrieve_document(state: GraphState) -> GraphState:
# 질문을 상태에서 가져옵니다.
latest_question = state["question"]
# 문서에서 검색하여 관련성 있는 문서를 찾습니다.
retrieved_docs = pdf_retriever.invoke(latest_question)
# 검색된 문서를 형식화합니다.(프롬프트 입력으로 넣어주기 위함)
retrieved_docs = format_docs(retrieved_docs)
# 검색된 문서를 context 키에 저장합니다.
return GraphState(context=retrieved_docs)
# 답변 생성 노드
def llm_answer(state: GraphState) -> GraphState:
# 질문을 상태에서 가져옵니다.
latest_question = state["question"]
# 검색된 문서를 상태에서 가져옵니다.
context = state["context"]
# 체인을 호출하여 답변을 생성합니다.
response = pdf_chain.invoke(
{
"question": latest_question,
"context": context,
"chat_history": messages_to_history(state["messages"]),
}
)
# 생성된 답변, (유저의 질문, 답변) 메시지를 상태에 저장합니다.
return GraphState(
answer=response, messages=[("user", latest_question), ("assistant", response)]
)
# 관련성 체크 노드
def relevance_check(state: GraphState) -> GraphState:
# 관련성 평가기를 생성합니다.
question_answer_relevant = GroundednessChecker(
llm=ChatOpenAI(model="gpt-4o-mini", temperature=0), target="question-retrieval"
).create()
# 관련성 체크를 실행("yes" or "no")
response = question_answer_relevant.invoke(
{"question": state["question"], "context": state["context"]}
)
print("==== [RELEVANCE CHECK] ====")
print(response.score)
# 참고: 여기서의 관련성 평가기는 각자의 Prompt 를 사용하여 수정할 수 있습니다. 여러분들의 Groundedness Check 를 만들어 사용해 보세요!
return GraphState(relevance=response.score)
# 관련성 체크하는 함수(router)
def is_relevant(state: GraphState) -> GraphState:
if state["relevance"] == "yes":
return "relevant"
else:
return "not relevant"
검색 노드 추가
- 이번에는 TavilySearch 도구를 사용하여 Web Search 를 수행합니다.
- 아래는 TavilySearch 도구를 사용한 예제입니다.
from langchain_teddynote.tools.tavily import TavilySearch
# 검색 도구 생성
tavily_tool = TavilySearch()
search_query = "2024년 노벨 문학상 수상자는?"
# 다양한 파라미터를 사용한 검색 예제
search_result = tavily_tool.search(
query=search_query, # 검색 쿼리
max_results=3, # 최대 검색 결과
format_output=True, # 결과 포맷팅
)
# 검색 결과 출력
print(search_result)
# 검색 노드로 패키징하여 추가합니다. (함수 생성)
# Web Search 노드
def web_search(state: GraphState) -> GraphState:
# 검색 도구 생성
tavily_tool = TavilySearch()
search_query = state["question"]
# 다양한 파라미터를 사용한 검색 예제
search_result = tavily_tool.search(
query=search_query, # 검색 쿼리
topic="general", # 일반 주제
max_results=6, # 최대 검색 결과
format_output=True, # 결과 포맷팅
)
return {"context": search_result}
Edges
- Edges: 현재 State를 기반으로 다음에 실행할 Node를 결정하는 Python 함수.
- 일반 엣지, 조건부 엣지 등이 있습니다.
from langgraph.graph import END, StateGraph
from langgraph.checkpoint.memory import MemorySaver
# 그래프 정의
workflow = StateGraph(GraphState)
# 노드 추가
workflow.add_node("retrieve", retrieve_document)
workflow.add_node("relevance_check", relevance_check)
workflow.add_node("llm_answer", llm_answer)
# Web Search 노드 추가
workflow.add_node("web_search", web_search)
# 엣지 추가
workflow.add_edge("retrieve", "relevance_check") # 검색 -> 관련성 체크
# 조건부 엣지를 추가합니다.
workflow.add_conditional_edges(
"relevance_check", # 관련성 체크 노드에서 나온 결과를 is_relevant 함수에 전달합니다.
is_relevant,
{
"relevant": "llm_answer", # 관련성이 있으면 답변을 생성합니다.
"not relevant": "web_search", # 관련성이 없으면 웹 검색을 수행합니다.
},
)
workflow.add_edge("web_search", "llm_answer") # 검색 -> 답변
workflow.add_edge("llm_answer", END) # 답변 -> 종료
# 그래프 진입점 설정
workflow.set_entry_point("retrieve")
# 체크포인터 설정
memory = MemorySaver()
# 그래프 컴파일
app = workflow.compile(checkpointer=memory)
# 컴파일한 그래프를 시각화
visualize_graph(app)
그래프 실행
- config 파라미터는 그래프 실행 시 필요한 설정 정보를 전달합니다.
- recursion_limit: 그래프 실행 시 재귀 최대 횟수를 설정합니다.
- inputs: 그래프 실행 시 필요한 입력 정보를 전달합니다.
- 검색 결과의 relevance_check 가 실패할 경우, 검색을 수행하여 웹 검색 결과를 제공합니다.
from langchain_core.runnables import RunnableConfig
from langchain_teddynote.messages import stream_graph, invoke_graph, random_uuid
# config 설정(재귀 최대 횟수, thread_id)
config = RunnableConfig(recursion_limit=10, configurable={"thread_id": random_uuid()})
# 질문 입력
inputs = GraphState(question="2024년 노벨 문학상 수상자는?")
# 그래프 실행
invoke_graph(app, inputs, config, ["relevance_check", "llm_answer"])
# 그래프 스트리밍 출력
stream_graph(app, inputs, config, ["relevance_check", "llm_answer"])
# 최종 출력 확인
outputs = app.get_state(config).values
print(f'Question: {outputs["question"]}')
print("===" * 20)
print(f'Answer:\\n{outputs["answer"]}')
'Lecture > 패스트캠퍼스' 카테고리의 다른 글
| 패스트캠퍼스 환급챌린지 37일차 : 테디노트의 RAG 비법노트 강의 후기 (3) | 2025.08.06 |
|---|---|
| 패스트캠퍼스 환급챌린지 36일차 : 테디노트의 RAG 비법노트 강의 후기 (2) | 2025.08.05 |
| 패스트캠퍼스 환급챌린지 34일차 : 테디노트의 RAG 비법노트 강의 후기 (1) | 2025.08.03 |
| 패스트캠퍼스 환급챌린지 33일차 : 테디노트의 RAG 비법노트 강의 후기 (0) | 2025.08.02 |
| 패스트캠퍼스 환급챌린지 32일차 : 테디노트의 RAG 비법노트 강의 후기 (1) | 2025.08.01 |
'Lecture/패스트캠퍼스' Related Articles
more




Comments