
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 함수형 프로그래밍
- TDD
- 싱글톤
- consumer
- junit5
- Stream
- 인텔리제이 단축키
- Java
- mokito
- SpringBoot
- JWT
- Authentication
- 패스트캠퍼스 #환급챌린지 #패스트캠퍼스후기 #습관형성 #직장인자기계발 #오공완
- topic
- Functional Programming
- 카프카
- orelse
- producer
- git cli
- Spring Security
- 디자인패턴
- #패스트캠퍼스 #환급챌린지 #패스트캠퍼스후기 #습관형성 #직장인자기계발 #오공완
- Clean Code
- Java8
- orElseGet
- kafka
- optional
- effective java
- signWith
- Factory Method Pattern
- Today
- Total
goodbye
패스트캠퍼스 환급챌린지 45일차 : 테디노트의 RAG 비법노트 강의 후기 본문
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다
https://fastcampus.info/4n8ztzq
(~6/20) 50일의 기적 AI 환급반💫 | 패스트캠퍼스
초간단 미션! 하루 20분 공부하고 수강료 전액 환급에 AI 스킬 장착까지!
fastcampus.co.kr
패스트캠퍼스 환급챌린지 45일차!
1) 공부 시작 시간 인증
2) 공부 종료 시간 인증
3) 강의 수강 클립 인증

4) 학습 인증샷
5) 학습통계

Today I Learned
평가 개념
AI 애플리케이션의 품질과 개발 속도는 종종 고품질 평가 데이터 세트와 측정 항목에 의해 제한되는데, 이를 통해 애플리케이션을 최적화하고 테스트할 수 있습니다.
LangSmith는 고품질 평가 구축을 쉽게 해줍니다. 이 가이드에서는 LangSmith 평가 프레임워크와 AI 평가 기법을 보다 폭넓게 설명합니다. LangSmith 프레임워크의 구성 요소는 다음과 같습니다.
데이터 세트는 애플리케이션을 평가하는 데 사용되는 예제들의 집합입니다. 테스트 입력과 참조 출력 쌍이 그 예입니다.
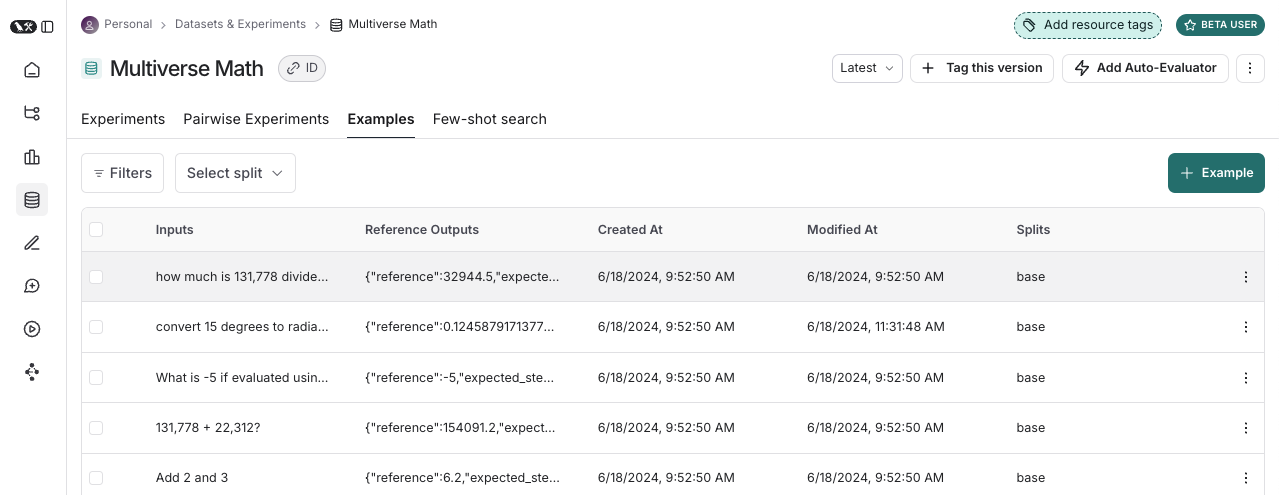
각 예는 다음으로 구성됩니다.
- 입력 : 애플리케이션에 전달할 입력 변수의 사전입니다.
- 참조 출력 (선택 사항): 참조 출력 사전입니다. 애플리케이션에 전달되지 않고 평가자에서만 사용됩니다.
- 메타데이터 (선택 사항): 데이터 세트의 필터링된 뷰를 생성하는 데 사용할 수 있는 추가 정보 사전입니다.
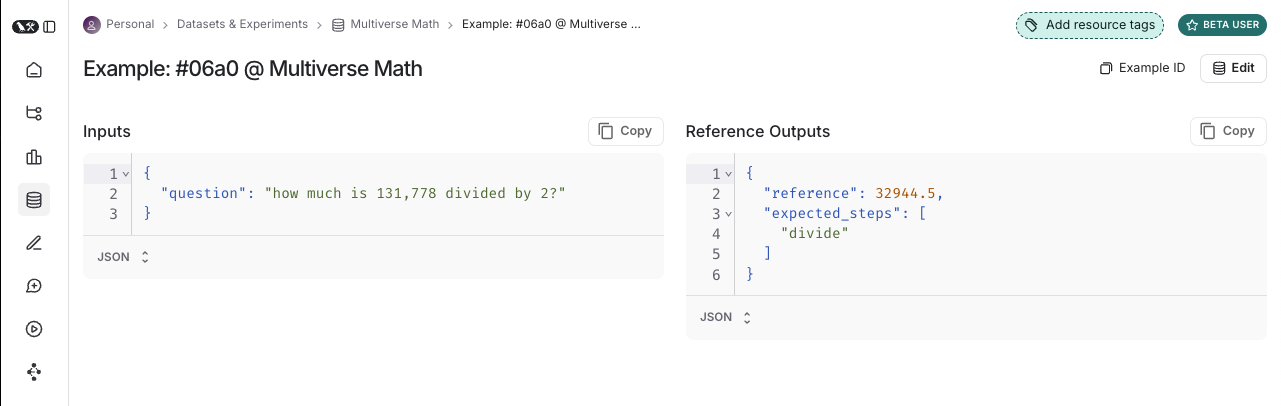
데이터셋
평가를 위한 데이터 세트를 구축하는 방법은 다양합니다. 여기에는 다음이 포함됩니다.
수동으로 큐레이팅된
일반적으로 데이터세트 생성을 시작할 때 다음과 같은 방법을 권장합니다. 애플리케이션을 구축하는 과정에서 애플리케이션이 어떤 유형의 입력을 처리할 수 있을지, 그리고 어떤 "좋은" 응답이 나올지 어느 정도 파악하셨을 것입니다. 몇 가지 일반적인 예외 사례나 상상할 수 있는 상황을 다루고 싶으실 겁니다. 직접 엄선한 고품질 예시 10~20개만 있어도 큰 도움이 될 수 있습니다.
역사적
애플리케이션을 프로덕션 환경에 구축하면 사용자가 실제로 어떻게 사용하고 있는지 등 귀중한 정보를 얻을 수 있습니다. 이러한 실제 운영 사례는 가장 현실적인 예시이기 때문에 좋은 사례가 될 수 있습니다!
트래픽이 많은 경우, 어떤 런을 데이터세트에 추가하는 것이 가치 있는지 어떻게 판단할 수 있을까요? 다음과 같은 몇 가지 방법을 활용할 수 있습니다.
- 사용자 피드백 : 가능하다면 최종 사용자 피드백을 수집해 보세요. 그러면 어떤 데이터 포인트가 부정적인 피드백을 받았는지 확인할 수 있습니다. 이는 매우 중요합니다! 이는 애플리케이션의 성능이 저하된 부분입니다. 이러한 부분을 데이터세트에 추가하여 향후 테스트에 활용하는 것이 좋습니다.
- 휴리스틱 : 다른 휴리스틱을 사용하여 "흥미로운" 데이터 포인트를 식별할 수도 있습니다. 예를 들어, 완료하는 데 오랜 시간이 걸린 실행은 데이터세트에 추가하고 분석하는 데 흥미로울 수 있습니다.
- LLM 피드백 : 다른 LLM을 사용하여 주목할 만한 실행을 감지할 수 있습니다. 예를 들어, 사용자가 질문을 다시 표현하거나 모델을 수정해야 했던 챗봇 대화에 LLM을 사용하여 라벨을 지정하여 챗봇이 처음에 올바르게 응답하지 않았음을 나타낼 수 있습니다.
합성
몇 가지 예시를 확보하면 인위적으로 더 많은 예시를 만들어 볼 수 있습니다. 일반적으로 이 전에 몇 가지 훌륭한 수작업 예시를 준비해 두는 것이 좋습니다. 합성 데이터는 어떤 면에서는 기존 데이터와 유사할 수 있기 때문입니다. 이는 많은 데이터 포인트를 빠르게 확보하는 데 유용한 방법이 될 수 있습니다.
평가를 설정할 때 데이터 세트를 여러 분할로 나눌 수 있습니다. 예를 들어, 빠르고 비용이 적게 드는 반복 작업에는 작은 분할을 사용하고, 최종 평가에는 큰 분할을 사용할 수 있습니다. 또한, 분할은 실험의 해석 가능성에도 중요할 수 있습니다. 예를 들어, RAG 애플리케이션의 경우, 데이터 세트를 다양한 유형의 질문(예: 사실 기반, 의견 등)에 집중하고 각 분할에 대해 애플리케이션을 개별적으로 평가할 수 있습니다.
데이터 세트 분할을 생성하고 관리하는 방법을 알아보세요 .
데이터세트는 버전 관리 되므로 데이터세트에 예제를 추가, 업데이트 또는 삭제할 때마다 새 버전의 데이터세트가 생성됩니다. 이를 통해 실수가 발생했을 때 데이터세트의 변경 사항을 쉽게 검토하고 되돌릴 수 있습니다. 또한 데이터세트 버전 에 태그를 지정하여 사람이 읽기 쉬운 이름을 지정할 수 있습니다. 이는 데이터세트 기록에서 중요한 이정표를 표시하는 데 유용할 수 있습니다.
데이터 세트의 특정 버전에 대해 평가를 실행할 수 있습니다. 이는 CI에서 평가를 실행할 때 데이터 세트 업데이트로 인해 CI 파이프라인이 실수로 중단되는 것을 방지하는 데 유용할 수 있습니다.
평가자는 특정 예제에서 애플리케이션이 얼마나 잘 수행되는지 점수를 매기는 기능입니다.
평가자
평가자는 다음과 같은 입력을 받습니다.
- 예 : 데이터세트 의 예시입니다 . 입력, (참조) 출력 및 메타데이터를 포함합니다.
- 실행 : 예제 입력을 애플리케이션에 전달하여 실제 출력과 중간 단계(자식 실행)를 생성합니다.
평가자
평가자는 하나 이상의 메트릭을 반환합니다. 이러한 메트릭은 다음과 같은 형식의 사전 또는 사전 목록으로 반환되어야 합니다.
- key: 메트릭의 이름입니다.
- score| value: 지표의 값입니다. score수치형 지표이거나 value범주형 지표인 경우 사용합니다.
- comment(선택 사항): 점수를 정당화하는 추론이나 추가 문자열 정보입니다.
정의
평가자를 정의하고 실행하는 방법에는 여러 가지가 있습니다.
- 사용자 정의 코드 : 사용자 정의 평가자를 Python 또는 TypeScript 함수로 정의하고 SDK를 사용하여 클라이언트 측에서 실행하거나 UI를 통해 서버 측에서 실행합니다.
- 내장 평가기 : LangSmith에는 UI를 통해 구성하고 실행할 수 있는 여러 내장 평가기가 있습니다.
LangSmith SDK( Python 및 TypeScript ) 를 사용하거나 Prompt Playground를 통해 평가자를 실행하거나 특정 추적 프로젝트나 데이터 세트에서 자동으로 평가자를 실행하도록 규칙을 구성하여 평가자를 실행할 수 있습니다.
평가
LLM 평가에는 몇 가지 고급 접근 방식이 있습니다.
인적 평가는 종종 평가의 좋은 시작점이 됩니다 . LangSmith를 사용하면 LLM 지원서 출력물과 추적(모든 중간 단계)을 쉽게 검토할 수 있습니다.
LangSmith의 주석 대기열을 사용하면 애플리케이션 출력에 대한 사람의 피드백을 쉽게 얻을 수 있습니다.
휴리스틱 평가기는 결정론적이고 규칙 기반 함수입니다. 챗봇의 응답이 비어 있지 않은지, 생성된 코드 조각을 컴파일할 수 있는지, 또는 분류가 정확히 맞는지 확인하는 것과 같은 간단한 검사에 유용합니다.
LLM
LLM 심사위원은 LLM을 사용하여 지원서의 결과물을 평가합니다. LLM을 사용하려면 일반적으로 LLM 프롬프트에 채점 규칙/기준을 인코딩합니다. LLM은 참조 없이 실행될 수 있습니다(예: 시스템 결과물에 부적절한 내용이 포함되어 있거나 특정 기준을 준수하는지 확인). 또는 과제 결과물을 참조 결과물과 비교할 수 있습니다(예: 결과물이 참조 결과물과 비교하여 사실적으로 정확한지 확인).
LLM 심사위원 평가자의 경우, 결과 점수를 신중하게 검토하고 필요한 경우 채점 기준을 조정하는 것이 중요합니다. 채점 기준에 입력, 출력, 예상 성적 등의 예시를 제시하는 단발성 평가자(four-shot evaluators)로 작성하는 것이 도움이 되는 경우가 많습니다.
LLM을 심사위원 평가자로 정의하는 방법 에 대해 알아보세요 .
쌍별 평가기를 사용하면 두 버전의 애플리케이션 출력을 비교할 수 있습니다. LMSYS Chatbot Arena를 생각해 보세요 . 이는 동일한 개념이지만, 모델뿐만 아니라 AI 애플리케이션 전반에 적용됩니다! 이는 휴리스틱("어느 답변이 더 긴가"), LLM(특정 쌍별 프롬프트 포함), 또는 사람(예시를 수동으로 주석으로 처리하도록 요청)을 사용할 수 있습니다.
쌍평가는 언제 사용해야 하나요?
쌍별 평가는 LLM 산출물을 직접 채점하기 어려울 때 유용하지만, 두 산출물을 비교하는 것은 더 쉽습니다. 요약과 같은 과제의 경우가 그렇습니다. 요약에 절대 점수를 매기기는 어려울 수 있지만, 두 요약 중 어느 것이 더 유익한지 선택하는 것은 쉽습니다.
쌍별 평가를 실행하는 방법을 알아보세요 .
데이터세트에서 애플리케이션을 평가할 때마다 실험을 수행합니다. 실험에는 데이터세트에서 특정 버전의 애플리케이션을 실행한 결과가 포함됩니다. LangSmith 실험 뷰 사용 방법을 알아보려면 실험 결과 분석 방법을 참조하세요 .

일반적으로 주어진 데이터세트에 대해 여러 실험을 실행하여 애플리케이션의 다양한 구성(예: 다양한 프롬프트 또는 LLM)을 테스트합니다. LangSmith에서는 데이터세트와 관련된 모든 실험을 쉽게 확인할 수 있습니다. 또한, 비교 뷰에서 여러 실험을 비교할 수 있습니다 .

주석
사람의 피드백은 애플리케이션에서 수집할 수 있는 가장 가치 있는 피드백인 경우가 많습니다. 애노테이션 대기열을 사용하면 애플리케이션 실행에 애노테이션을 적용할 수 있습니다. 그러면 애노테이션 담당자는 대기열에 있는 실행을 간편하게 검토하고 피드백을 제공할 수 있습니다. 이렇게 애노테이션이 적용된 실행의 일부(일부)는 이후 평가를 위해 데이터세트 로 전송되는 경우가 많습니다. 실행에 인라인으로 애노테이션을 적용할 수도 있지만 , 애노테이션 대기열은 실행을 그룹화하고, 애노테이션 기준을 지정하고, 권한을 구성하는 또 다른 옵션을 제공합니다.
주석 대기열과 인간 피드백 에 대해 자세히 알아보세요 .
오프라인
데이터세트를 기반으로 애플리케이션을 평가하는 것을 "오프라인" 평가라고 합니다. 오프라인 평가는 미리 컴파일된 데이터세트를 기반으로 평가하기 때문에 오프라인입니다. 반면 온라인 평가는 배포된 애플리케이션의 출력을 실제 트래픽에 대해 거의 실시간으로 평가하는 것입니다. 오프라인 평가는 배포 전에 애플리케이션의 특정 버전을 테스트하는 데 사용됩니다.
LangSmith SDK( Python 및 TypeScript )를 사용하여 클라이언트 측에서 오프라인 평가를 실행할 수 있습니다. Prompt Playground를 사용하거나, 특정 데이터세트에 대해 모든 새로운 실험에 대해 특정 평가자를 실행하도록 자동화를 구성하여 서버 측에서 실행할 수 있습니다.
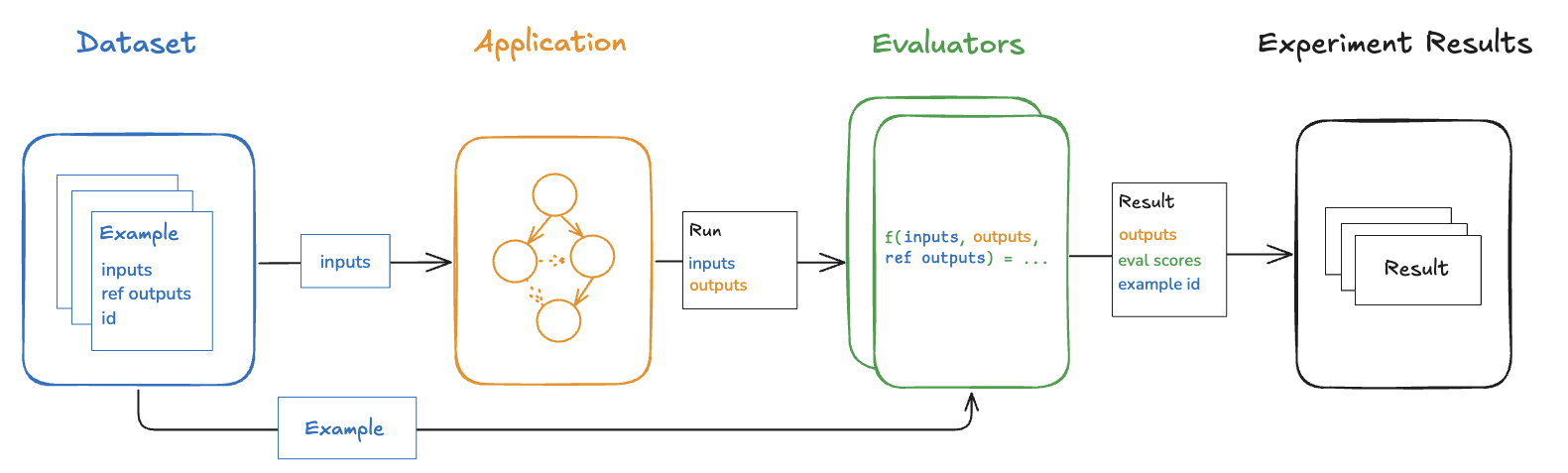
아마도 가장 일반적인 오프라인 평가 유형은 대표적인 입력 데이터 세트를 큐레이팅하고, 핵심 성과 지표를 정의하고, 여러 버전의 애플리케이션을 벤치마킹하여 최적의 버전을 찾는 것입니다. 벤치마킹은 많은 사용 사례에서 표준 참조 출력으로 데이터 세트를 큐레이팅하고 실험 출력과 이를 비교하기 위한 적절한 지표를 설계해야 하기 때문에 힘들 수 있습니다. RAG Q&A 봇의 경우 이는 질문과 참조 답변 데이터 세트, 그리고 실제 답변이 참조 답변과 의미적으로 동일한지 여부를 판단하는 LLM 평가자처럼 보일 수 있습니다. ReACT 에이전트의 경우 이는 사용자 요청 데이터 세트와 모델이 수행해야 하는 모든 도구 호출의 참조 세트, 그리고 모든 참조 도구 호출이 수행되었는지 확인하는 휴리스틱 평가자처럼 보일 수 있습니다.
단위
단위 테스트는 소프트웨어 개발에서 개별 시스템 구성 요소의 정확성을 검증하는 데 사용됩니다. LLM 맥락에서 단위 테스트는 LLM 입력 또는 출력에 대한 규칙 기반 단언(예: LLM에서 생성된 코드의 컴파일 가능 여부, JSON 로드 가능 여부 등)으로, 기본 기능을 검증하는 경우가 많습니다.
단위 테스트는 항상 통과해야 한다는 기대를 가지고 작성되는 경우가 많습니다. 이러한 유형의 테스트는 CI의 일부로 실행하기에 좋습니다. 이 경우 LLM 호출을 최소화하기 위해 캐시를 설정하는 것이 좋습니다(LLM 호출은 빠르게 누적될 수 있기 때문입니다!).
회귀
회귀 테스트는 시간 경과에 따라 애플리케이션 버전 간의 성능을 측정하는 데 사용됩니다. 최소한 새 앱 버전이 현재 버전에서 정상적으로 처리하는 예제에서 회귀하지 않는지 확인하고, 이상적으로는 새 버전이 현재 버전보다 얼마나 향상된지 측정하는 데 사용됩니다. 이러한 테스트는 사용자 경험에 영향을 미칠 것으로 예상되는 앱 업데이트(예: 모델 또는 아키텍처 업데이트)를 수행할 때 종종 트리거됩니다.
LangSmith의 비교 뷰는 회귀 테스트를 기본적으로 지원하므로 기준선 대비 변경된 사례를 빠르게 확인할 수 있습니다. 회귀는 빨간색으로, 개선 사항은 녹색으로 강조 표시됩니다.

백테스팅은 위에서 설명한 데이터 세트 생성과 평가를 결합하는 접근 방식입니다. 운영 로그가 있다면 이를 데이터 세트로 변환할 수 있습니다. 그런 다음, 해당 운영 사례를 최신 애플리케이션 버전으로 다시 실행할 수 있습니다. 이를 통해 과거 및 실제 사용자 입력을 기반으로 성과를 평가할 수 있습니다.
이는 일반적으로 새 모델 버전을 평가하는 데 사용됩니다. Anthropic에서 새 모델을 출시했다고요? 문제없습니다! 애플리케이션에서 가장 최근 실행된 1,000개의 결과를 가져와 새 모델에 적용하세요. 그런 다음 해당 결과를 실제 운영 환경에서 발생한 결과와 비교하세요.
쌍별
어떤 과제의 경우, 사람이나 LLM 채점자가 "A 버전이 B 버전보다 나은지" 판단하는 것이 A 버전이나 B 버전에 절대 점수를 부여하는 것보다 더 쉽습니다. 쌍대 평가는 바로 이러한 방식입니다. 즉, 두 버전의 결과를 특정 참조 결과나 절대 기준에 따라 점수를 매기는 것이 아니라 서로 비교하는 것입니다. 쌍대 평가는 LLM 심사위원이 보다 일반적인 과제에 참여할 때 종종 유용합니다. 예를 들어, 요약 작성 애플리케이션이 있는 경우, LLM 심사위원이 "이 두 요약 중 어느 것이 더 명확하고 간결한가?"를 판단하는 것이 "명확성과 간결성 측면에서 이 요약에 1~10점을 주십시오."와 같은 절대 점수를 부여하는 것보다 더 쉬울 수 있습니다.
쌍별 평가를 실행하는 방법을 알아보세요 .
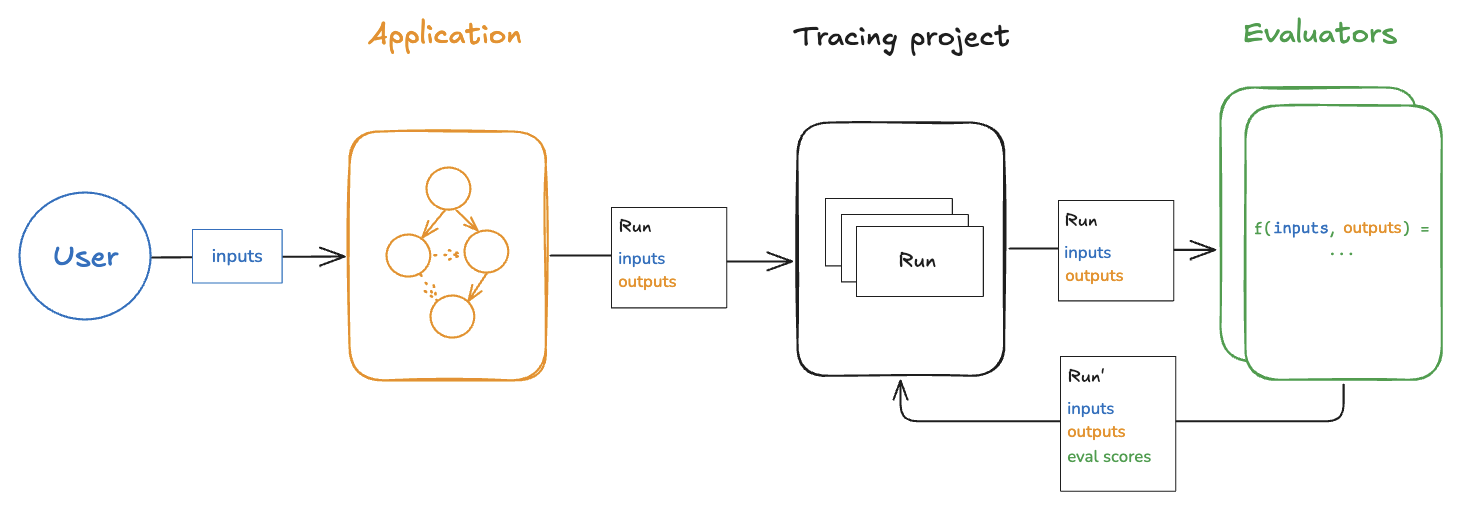
온라인
배포된 애플리케이션의 출력을 (거의) 실시간으로 평가하는 것을 "온라인" 평가라고 합니다. 이 경우 데이터세트가 사용되지 않으며 참조 출력도 존재하지 않습니다. 실제 입력과 출력이 생성되는 즉시 평가기를 실행합니다. 이는 애플리케이션을 모니터링하고 의도치 않은 동작을 감지하는 데 유용합니다. 온라인 평가는 오프라인 평가와 함께 사용할 수도 있습니다. 예를 들어, 온라인 평가기를 사용하여 입력 질문을 여러 범주로 분류할 수 있으며, 이 범주는 나중에 오프라인 평가를 위한 데이터세트를 큐레이팅하는 데 사용될 수 있습니다.
온라인 평가기는 일반적으로 서버 측에서 실행되도록 설계되었습니다. LangSmith에는 사용자가 구성할 수 있는 LLM 심사 평가기가 내장되어 있으며 , LangSmith 내에서 실행되는 사용자 지정 코드 평가기를 정의할 수도 있습니다.
'Lecture > 패스트캠퍼스' 카테고리의 다른 글
| 패스트캠퍼스 환급챌린지 47일차 : 테디노트의 RAG 비법노트 강의 후기 (3) | 2025.08.16 |
|---|---|
| 패스트캠퍼스 환급챌린지 46일차 : 테디노트의 RAG 비법노트 강의 후기 (4) | 2025.08.15 |
| 패스트캠퍼스 환급챌린지 44일차 : 테디노트의 RAG 비법노트 강의 후기 (1) | 2025.08.13 |
| 패스트캠퍼스 환급챌린지 43일차 : 테디노트의 RAG 비법노트 강의 후기 (6) | 2025.08.12 |
| 패스트캠퍼스 환급챌린지 42일차 : 테디노트의 RAG 비법노트 강의 후기 (3) | 2025.08.11 |



