
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 인텔리제이 단축키
- effective java
- consumer
- SpringBoot
- 패스트캠퍼스 #환급챌린지 #패스트캠퍼스후기 #습관형성 #직장인자기계발 #오공완
- junit5
- Java8
- 디자인패턴
- 카프카
- 함수형 프로그래밍
- orElseGet
- topic
- Functional Programming
- mokito
- Spring Security
- TDD
- JWT
- Stream
- orelse
- 싱글톤
- Clean Code
- signWith
- optional
- Java
- #패스트캠퍼스 #환급챌린지 #패스트캠퍼스후기 #습관형성 #직장인자기계발 #오공완
- git cli
- Authentication
- producer
- Factory Method Pattern
- kafka
- Today
- Total
goodbye
패스트캠퍼스 환급챌린지 40일차 : 테디노트의 RAG 비법노트 강의 후기 본문
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다
https://fastcampus.info/4n8ztzq
(~6/20) 50일의 기적 AI 환급반💫 | 패스트캠퍼스
초간단 미션! 하루 20분 공부하고 수강료 전액 환급에 AI 스킬 장착까지!
fastcampus.co.kr
패스트캠퍼스 환급챌린지 40일차!
1) 공부 시작 시간 인증
2) 공부 종료 시간 인증
3) 강의 수강 클립 인증
4) 학습 인증샷

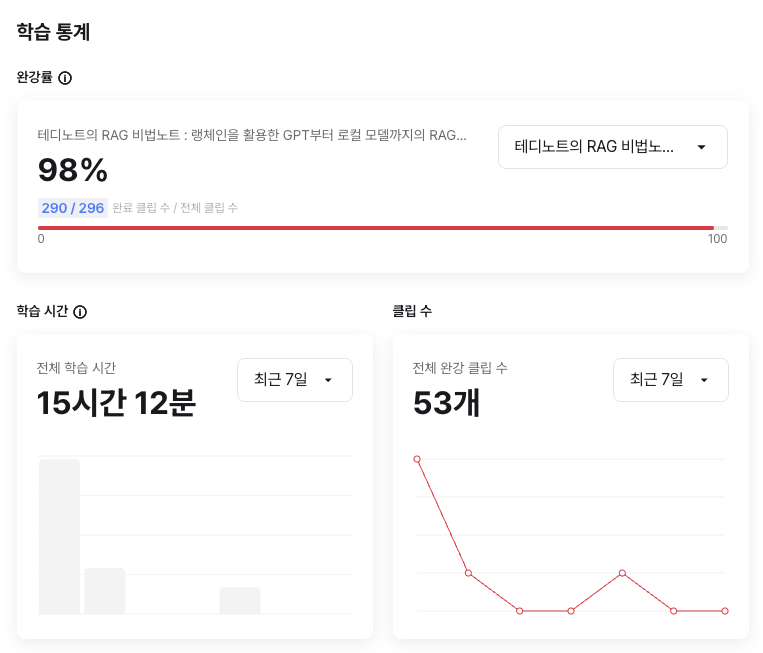
5) 학습통계
Today I Learned
CSV/Excel 데이터 분석 Agent
Pandas DataFrame 을 활용하여 분석을 수행하는 Agent 를 생성할 수 있습니다.
CSV/Excel 데이터로부터 Pandas DataFrame 객체를 생성할 수 있으며, 이를 활용하여 Agent 가 Pandas query 를 생성하여 분석을 수행할 수 있습니다.
# API 키를 환경변수로 관리하기 위한 설정 파일
from dotenv import load_dotenv
import pandas as pd
# API 키 정보 로드
load_dotenv()
df = pd.read_csv("./data/titanic.csv") # CSV 파일을 읽습니다.
# df2 = pd.read_excel("./data/titanic.xlsx", sheet_name="Sheet1") # 엑셀 파일도 읽을 수 있습니다.
df.head()
from langchain_experimental.tools import PythonAstREPLTool
# 파이썬 코드를 실행하는 도구를 생성합니다.
python_tool = PythonAstREPLTool()
python_tool.locals["df"] = df
# 도구 호출 시 실행되는 콜백 함수입니다.
def tool_callback(tool) -> None:
print(f"<<<<<<< Code >>>>>>")
if tool_name := tool.get("tool"): # 도구에 입력된 값이 있다면
if tool_name == "python_repl_ast":
tool_input = tool.get("tool_input")
for k, v in tool_input.items():
if k == "query":
print(v) # Query 를 출력합니다.
result = python_tool.invoke({"query": v})
print(result)
print(f"<<<<<<< Code >>>>>>")
# 관찰 결과를 출력하는 콜백 함수입니다.
def observation_callback(observation) -> None:
print(f"<<<<<<< Message >>>>>>")
if "observation" in observation:
print(observation["observation"])
print(f"<<<<<<< Message >>>>>>")
# 최종 결과를 출력하는 콜백 함수입니다.
def result_callback(result: str) -> None:
print(f"<<<<<<< 최종 답변 >>>>>>")
print(result)
print(f"<<<<<<< 최종 답변 >>>>>>")
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain.agents.agent_types import AgentType
from langchain_openai import ChatOpenAI
from langchain_teddynote.messages import AgentStreamParser, AgentCallbacks
agent = create_pandas_dataframe_agent(
ChatOpenAI(model="gpt-4o", temperature=0),
df,
verbose=False,
agent_type="tool-calling",
allow_dangerous_code=True,
prefix="You are a professional data analyst and expert in Pandas. "
"You must use Pandas DataFrame(`df`) to answer user's request. "
"\\n\\n[IMPORTANT] DO NOT create or overwrite the `df` variable in your code. \\n\\n"
"If you are willing to generate visualization code, please use `plt.show()` at the end of your code. "
"I prefer seaborn code for visualization, but you can use matplotlib as well."
"\\n\\n<Visualization Preference>\\n"
"- `muted` cmap, white background, and no grid for your visualization."
"\\nRecomment to set palette parameter for seaborn plot.",
)
parser_callback = AgentCallbacks(tool_callback, observation_callback, result_callback)
stream_parser = AgentStreamParser(parser_callback)
def ask(query):
# 질의에 대한 답변을 출력합니다.
response = agent.stream({"input": query})
for step in response:
stream_parser.process_agent_steps(step)
# 질의에 대한 답변을 출력합니다.
response = agent.stream({"input": "corr() 을 구해서 히트맵 시각화"})
for step in response:
stream_parser.process_agent_steps(step)
ask("몇 개의 행이 있어?")
ask("남자와 여자의 생존율의 차이는 몇이야?")
ask("남자 승객과 여자 승객의 생존율을 구한뒤 barplot 차트로 시각화 해줘")
ask("1,2 등급에 탑승한 10세 이하 어린 아이의 성별별 생존율을 구하고 시각화 하세요")
Toolkits 활용 Agent
LangChain 프레임워크를 사용하는 가장 큰 이점은 3rd-party integration 되어 있는 다양한 기능들입니다.
그 중 Toolkits 는 다양한 도구를 통합하여 제공합니다.
아래 링크에서 다양한 Tools/Toolkits 를 확인할 수 있습니다.
# API 키를 환경변수로 관리하기 위한 설정 파일
from dotenv import load_dotenv
# API 키 정보 로드
load_dotenv()
Toolkits 활용 Agent
LangChain 프레임워크를 사용하는 가장 큰 이점은 3rd-party integration 되어 있는 다양한 기능들입니다.
그 중 Toolkits 는 다양한 도구를 통합하여 제공합니다.
아래 링크에서 다양한 Tools/Toolkits 를 확인할 수 있습니다.
참고
FileManagementToolkit
FileManagementToolkit 는 로컬 파일 관리를 위한 도구 모음입니다.
주요 구성 요소
파일 관리 도구들
- CopyFileTool: 파일 복사
- DeleteFileTool: 파일 삭제
- FileSearchTool: 파일 검색
- MoveFileTool: 파일 이동
- ReadFileTool: 파일 읽기
- WriteFileTool: 파일 쓰기
- ListDirectoryTool: 디렉토리 목록 조회
설정
- root_dir: 파일 작업의 루트 디렉토리 설정 가능
- selected_tools: 특정 도구만 선택적으로 사용 가능
동적 도구 생성
- get_tools 메서드로 선택된 도구들의 인스턴스 생성
이 FileManagementToolkit은 로컬 파일 관리 작업을 자동화하거나 AI 에이전트에게 파일 조작 능력을 부여할 때 유용하게 사용할 수 있습니다. 단, 보안 측면에서 신중한 접근이 필요합니다.
# FileManagementToolkit을 가져옵니다. 이 도구는 파일 관리 작업을 수행하는 데 사용됩니다.
from langchain_community.agent_toolkits import FileManagementToolkit
# 'tmp'라는 이름의 디렉토리를 작업 디렉토리로 설정합니다.
working_directory = "tmp"
# FileManagementToolkit 객체를 생성합니다.
# root_dir 매개변수에 작업 디렉토리를 지정하여 모든 파일 작업이 이 디렉토리 내에서 이루어지도록 합니다.
toolkit = FileManagementToolkit(root_dir=str(working_directory))
# toolkit.get_tools() 메서드를 호출하여 사용 가능한 모든 파일 관리 도구를 가져옵니다.
# 이 도구들은 파일 복사, 삭제, 검색, 이동, 읽기, 쓰기, 디렉토리 목록 조회 등의 기능을 제공합니다.
available_tools = toolkit.get_tools()
# 사용 가능한 도구들의 이름을 출력합니다.
print("[사용 가능한 파일 관리 도구들]")
for tool in available_tools:
print(f"- {tool.name}: {tool.description}")
# 도구 중 일부만 지정하여 선택하는 것도 가능합니다
tools = FileManagementToolkit(
root_dir=str(working_directory),
selected_tools=["read_file", "file_delete", "write_file", "list_directory"],
).get_tools()
tools
read_tool, delete_tool, write_tool, list_tool = tools
# 파일 쓰기
write_tool.invoke({"file_path": "example.txt", "text": "Hello World!"})
# 파일 목록 조회
print(list_tool.invoke({}))
# 파일 삭제
print(delete_tool.invoke({"file_path": "example.txt"}))
# 파일 목록 조회
print(list_tool.invoke({}))
# 필요한 모듈과 클래스를 임포트합니다.
from langchain.tools import tool
from typing import List, Dict
from langchain_teddynote.tools import GoogleNews
# 최신 뉴스 검색 도구를 정의합니다.
@tool
def latest_news(k: int = 5) -> List[Dict[str, str]]:
"""Look up latest news"""
# GoogleNews 객체를 생성합니다.
news_tool = GoogleNews()
# 최신 뉴스를 검색하고 결과를 반환합니다. k는 반환할 뉴스 항목의 수입니다.
return news_tool.search_latest(k=k)
# FileManagementToolkit을 사용하여 파일 관리 도구들을 가져옵니다.
tools = FileManagementToolkit(
root_dir=str(working_directory),
).get_tools()
# 최신 뉴스 검색 도구를 tools 리스트에 추가합니다.
tools.append(latest_news)
# 모든 도구들이 포함된 tools 리스트를 출력합니다.
tools
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.agents import create_tool_calling_agent, AgentExecutor
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_teddynote.messages import AgentStreamParser
# session_id 를 저장할 딕셔너리 생성
store = {}
# 프롬프트 생성
# 프롬프트는 에이전트에게 모델이 수행할 작업을 설명하는 텍스트를 제공합니다. (도구의 이름과 역할을 입력)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant. "
"Make sure to use the `latest_news` tool to find latest news. "
"Make sure to use the `file_management` tool to manage files. ",
),
("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
]
)
# LLM 생성
llm = ChatOpenAI(model="gpt-4o-mini")
# Agent 생성
agent = create_tool_calling_agent(llm, tools, prompt)
# AgentExecutor 생성
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=False,
handle_parsing_errors=True,
)
# session_id 를 기반으로 세션 기록을 가져오는 함수
def get_session_history(session_ids):
if session_ids not in store: # session_id 가 store에 없는 경우
# 새로운 ChatMessageHistory 객체를 생성하여 store에 저장
store[session_ids] = ChatMessageHistory()
return store[session_ids] # 해당 세션 ID에 대한 세션 기록 반환
# 채팅 메시지 기록이 추가된 에이전트를 생성합니다.
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
# 대화 session_id
get_session_history,
# 프롬프트의 질문이 입력되는 key: "input"
input_messages_key="input",
# 프롬프트의 메시지가 입력되는 key: "chat_history"
history_messages_key="chat_history",
)
agent_stream_parser = AgentStreamParser()
result = agent_with_chat_history.stream(
{
"input": "최신 뉴스 5개를 검색하고, 각 뉴스의 제목을 파일명으로 가지는 파일을 생성하고(.txt), "
"파일의 내용은 뉴스의 내용과 url을 추가하세요. "
},
config={"configurable": {"session_id": "abc123"}},
)
print("Agent 실행 결과:")
for step in result:
agent_stream_parser.process_agent_steps(step)
result = agent_with_chat_history.stream(
{
"input": "이전에 생성한 파일 제목 맨 앞에 제목에 어울리는 emoji를 추가하여 파일명을 변경하세요. "
"파일명도 깔끔하게 변경하세요. "
},
config={"configurable": {"session_id": "abc123"}},
)
print("Agent 실행 결과:")
for step in result:
agent_stream_parser.process_agent_steps(step)
result = agent_with_chat_history.stream(
{
"input": "이전에 생성한 모든 파일을 `news` 폴더를 생성한 뒤 해당 폴더에 모든 파일을 복사하세요. "
"내용도 동일하게 복사하세요. "
},
config={"configurable": {"session_id": "abc123"}},
)
print("Agent 실행 결과:")
for step in result:
agent_stream_parser.process_agent_steps(step)
result = agent_with_chat_history.stream(
{"input": "news 폴더를 제외한 모든 .txt 파일을 삭제하세요."},
config={"configurable": {"session_id": "abc123"}},
)
print("Agent 실행 결과:")
for step in result:
agent_stream_parser.process_agent_steps(step)
'Lecture > 패스트캠퍼스' 카테고리의 다른 글
| 패스트캠퍼스 환급챌린지 42일차 : 테디노트의 RAG 비법노트 강의 후기 (3) | 2025.08.11 |
|---|---|
| 패스트캠퍼스 환급챌린지 41일차 : 테디노트의 RAG 비법노트 강의 후기 (4) | 2025.08.10 |
| 패스트캠퍼스 환급챌린지 39일차 : 테디노트의 RAG 비법노트 강의 후기 (6) | 2025.08.08 |
| 패스트캠퍼스 환급챌린지 38일차 : 테디노트의 RAG 비법노트 강의 후기 (4) | 2025.08.07 |
| 패스트캠퍼스 환급챌린지 37일차 : 테디노트의 RAG 비법노트 강의 후기 (3) | 2025.08.06 |



